

















文章目錄
本篇內容包括:
- 匯入CSV資料
- 匯入錯誤訊息解決
- aggregate函數應用
- 用R語言實作SPSS單分組變量平均數法
- 用R語言實作SPSS雙分組變量平均數法
- 用factor函數轉換值為因子
這一篇讓我們用R語言來實作一個SPSS中常見的統計的比較平均數法,如何使用R語言中的功能來呈現。方法也許不止一種,主要希望可以用最簡單的方式讓原本只會使用SPSS圖形化介面的使用者,可以進入簡單的程式領域,用羅輯思考分析,理解用程式語言的角度來看統計分析。
匯入CSV資料
一般而言,如果用excel編輯完成後,再儲存成csv,通常會變成亂碼,為什麼知道是亂碼呢?一來匯入出問題,二來用sublime打開,就會發現了。所以保險起見,不管你是不是用excel編輯過檔案,都先用支援utf-8的編輯器確認一下吧!
這個部份,如果裡面沒有非英文字,通常非常順利,但一旦出問題,通常要花非常多的時間才能找到答案,甚至google了很久,花很多時間,搞的精疲力竭,仍然找不到正確的答案,畢竟魔鬼藏在細節裡。
確定資料格式(UTF-8)
這裡要特別注意的是,標題列如果包含非英文語系的字,像中文、日本或韓文等語系,建議使用支援UTF-8的編輯器(ex: Sublime)打開來確認一下內容,再重新存檔一次(格式UTF-8),才能避免底下的這些錯誤情況。
到底要不要加fileEncoding = “UTF-8″呢!
如果你有做前一項,基本上是不用加,都可以正常匯入資料。
匯入錯誤訊息
Error in read.table(file = file, header = header, sep = sep, quote = quote, :
empty beginning of file
Error in make.names(col.names, unique = TRUE) :
無效的多位元組字串於 ''
Warning messages:
1: In read.table(file = file, header = header, sep = sep, quote = quote, :
輸入連結 'bank.csv' 中的輸入不正確
2: In read.table(file = file, header = header, sep = sep, quote = quote, :
incomplete final line found by readTableHeader on 'bank.csv'
通常看到上述的錯誤訊息,正確的解決方法,請看看前一項,應該8成都可以解決。
函數:read.csv
saledata <- read.csv(file = "bank.csv", header = TRUE)
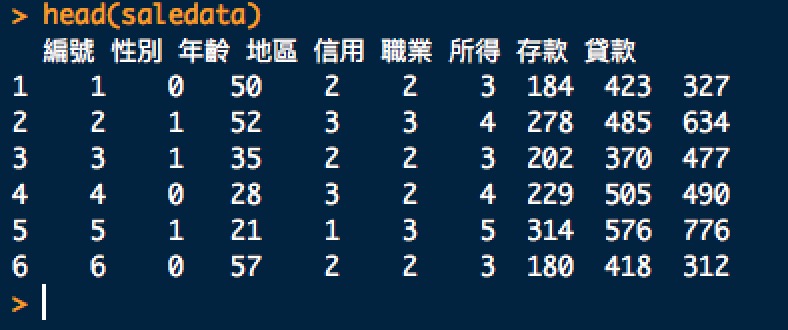
計算平均數
各族群各項變數之平均值為何?
案例:依性別之不同,計算出客戶平均貸款與平均存款。
實作分群
分群:性別
實作單分組變量比較平均數法
用myvars定義出要計算出來的客戶的平均貸款和平均存款。
myvars <- c("貸款","存款")
函數:aggregate()
aggregate(saledata[myvars], by=list(saledata$性別),mean)

這時候因為我們沒有定義分組的標籤名稱,系統用自動用Group.1代替性別,若我們想顯示出性別,就另外定義性別取代Group.1。
aggregate(saledata[myvars], by=list(性別=saledata$性別),mean)

實作雙分組變量比較平均數法
前一個案例是單因子,若是兩個因子呢?
案例:先依據性別之不同,再區分信用等級,計算出不用性別與信用等級下,客戶的平均貸款與平均存款。
aggregate(saledata[myvars], by=list(性別=saledata$性別,信用等級=saledata$信用等級),mean)
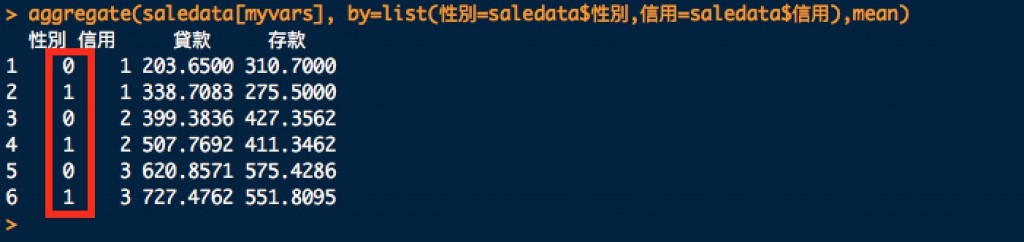
這時候,看似很完美的呈現了我們想要的結果,但是性別的部份,出現的卻是0和1,如何把0和1替換成男和女呢?
讓呈現出來的資料結果更人性化及更容易看的懂呢!
值標籤(value labels)
一般而言,解決方法有幾種,第一種,最省事,直接附註:0是男生1是女生;第二種,使用值標籤(value labels),將資料作轉換。
第一種不用說,不用教你我都會;讓我們來看第二種值標籤,將類別型態的值定義成新標籤。
函數:factor()
假設0是男生,1是女生。
將值轉換為因子(factor)
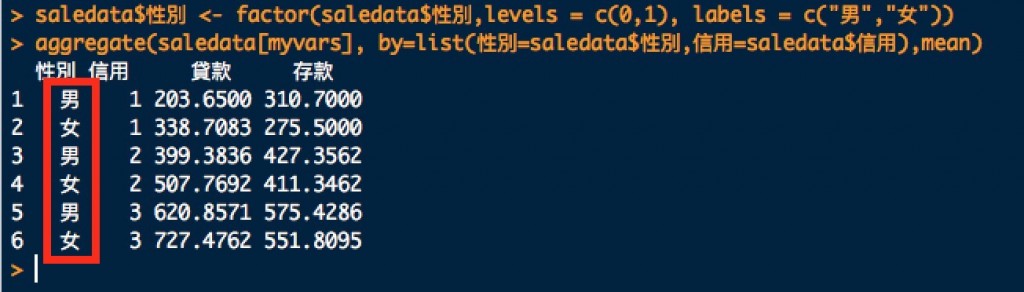
saledata$性別 <- factor(saledata$性別,levels = c(0,1), labels = c("男","女"))
aggregate(saledata[myvars], by=list(性別=saledata$性別,信用=saledata$信用),mean)
練習題
請依職業別之不同,計算出客戶平均所得與平均存款。




